So I started down the path of building an automated DFIR pipeline.
As mentioned previously, SANS announced an AI Hackathon, and my original idea was to automate the entire process end-to-end — including writing the report. The logic seemed clean: combine static detection scripts (rules-based alerts and detections), feed those into the LLM, have it dig deeper to answer follow-up questions about each alert, and then have it write the report.
The iterations
I went through several iterations down this path and honestly thought I was making good progress. The findings were reasonably consistent — but not always the same, and not always weighted the same way. I ran the LLM multiple times against the same alert output and got different findings each time. That inconsistency skews the report: a finding that wasn't a 100% true positive gets flagged, the LLM builds the narrative around it, and the whole report ends up tilted off that one shaky data point.
The realisation
Eventually I came to the conclusion: fully automated isn't the way to go. The LLM is an assistant, not something to be relied on 100%.
No matter what the AI vendors claim, the core issue is that these models are created to please the user. If you tell the LLM to find evil, it goes looking for evil — and every finding gets associated with being evil, even when it's not 100% confident. The framing biases the output.
So the way forward is a combination of automation and direct interaction with the AI as an assistant.
What the LLM produced
The section below is from the report written by the LLM. It includes only the findings that the human analyst still has to review and select from.
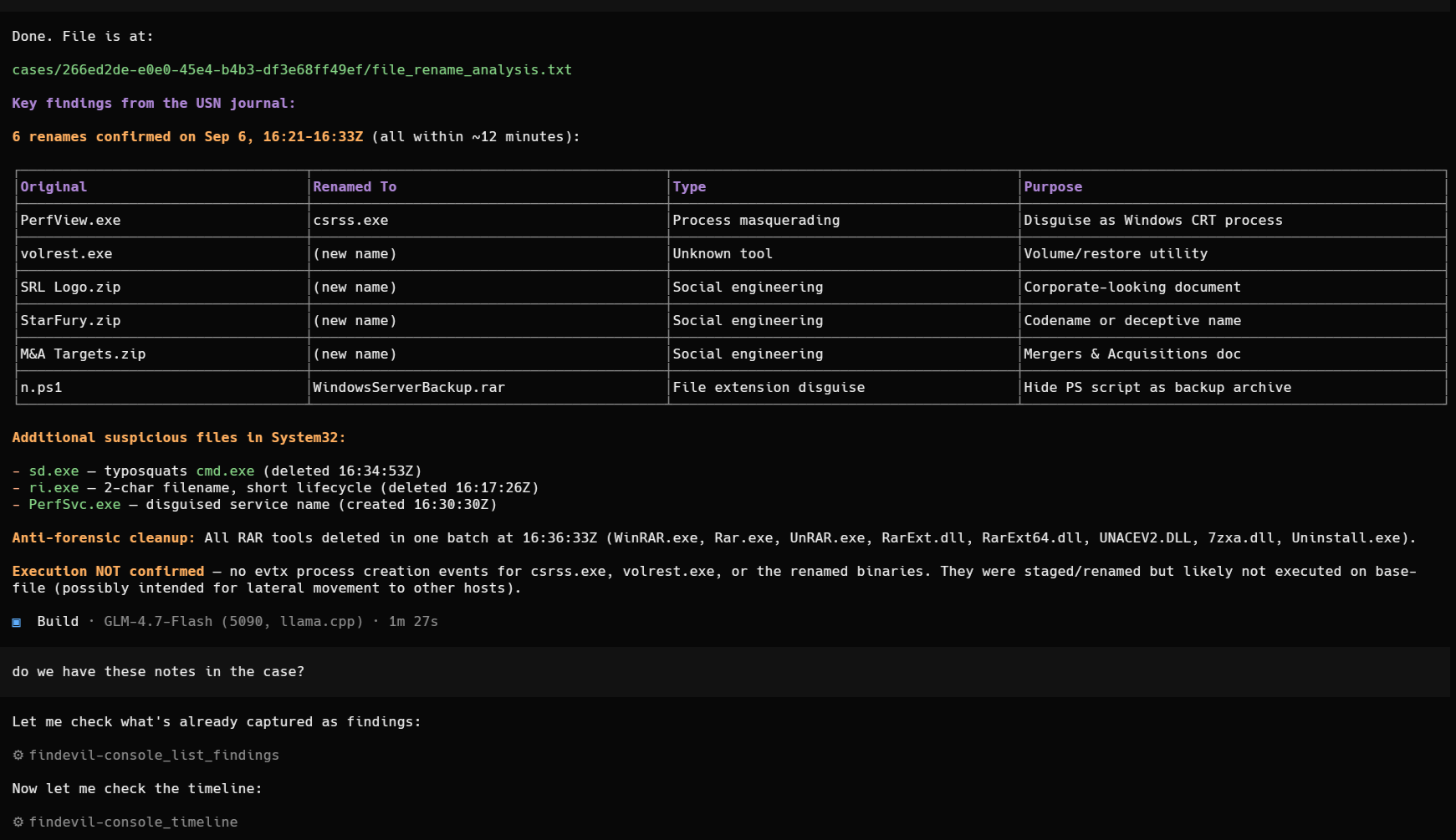

Is it perfect? No. Does it need to be?
This is by no means perfect, and honestly in my experience it isn't possible yet — and probably never will be. But do we actually need perfection? Even a fully manual investigation is never perfect. The real question is: can we find enough to present meaningful findings to the client, and — most importantly — is what we're presenting factually true rather than an AI hallucination?
I'm still iterating on this tool and it gets better every day.
The MVP
I'm also working on an MVP. So far:
- Frontend GUI with login
- Evidence upload, stored in an S3 bucket
- The automated analysis stage pulls the image down to the processing workstation
- Automated analysis runs, findings are uploaded back to the GUI
- The analyst picks up the manual investigation from there
More to come.