Let me get the bias out of the way first, because it shapes everything that follows.
I don't hold much weight in threat intel. Most of it is stale by the time it reaches you, and during an actual incident the IOCs rarely tell you anything about what's happening — an IP and a hash don't explain the intrusion, they just confirm you've seen the same furniture someone else saw three weeks ago. Infrastructure gets shared, rented, hijacked and abused by actors, scripts and bots alike, so tying any of it cleanly to a single threat actor is hard. And even when you can pin it to an actor, I'm not convinced it changes what you do next in the investigation. Knowing it's UNC-whatever is a nice line in the report; it doesn't tell you which box to image first.
Yet there's a whole industry selling this stuff, and — let's be honest — 99% of what they're repackaging is free and open source.
So obviously I built my own platform to play with it. All in the name of science.
I call it PulseTrace, and it lives quietly behind /security-feed.
What it actually does
The shape of it is simple and deliberately boring on the collection side, because that's the commodity bit:
- Poll a spread of sources. Vendor blogs, advisories, the usual open feeds. Nothing exotic.
- First-pass summary with a fast model. A small, cheap LLM does a quick triage summary so the feed is readable at a glance. This is the "is this worth my time" layer.
- Enrich on demand. If something's actually interesting, I hand it to the big model — a 397B running on my own cluster — which reads the entire original source, not a snippet, and produces a proper detailed write-up.
That enrichment step is the only part I think is genuinely worth anything, so it's where the work went.
The enrichment is the product, not the feed
When I enrich an item, the 397B isn't just rewriting the summary longer. It's doing the translation work that the original vendor post never does for my audience — EMEA financial services living under DORA and NIS2.
Take the Ivanti Connect Secure write-up it produced from Mandiant's "Cutting Edge, Part 3" reporting:

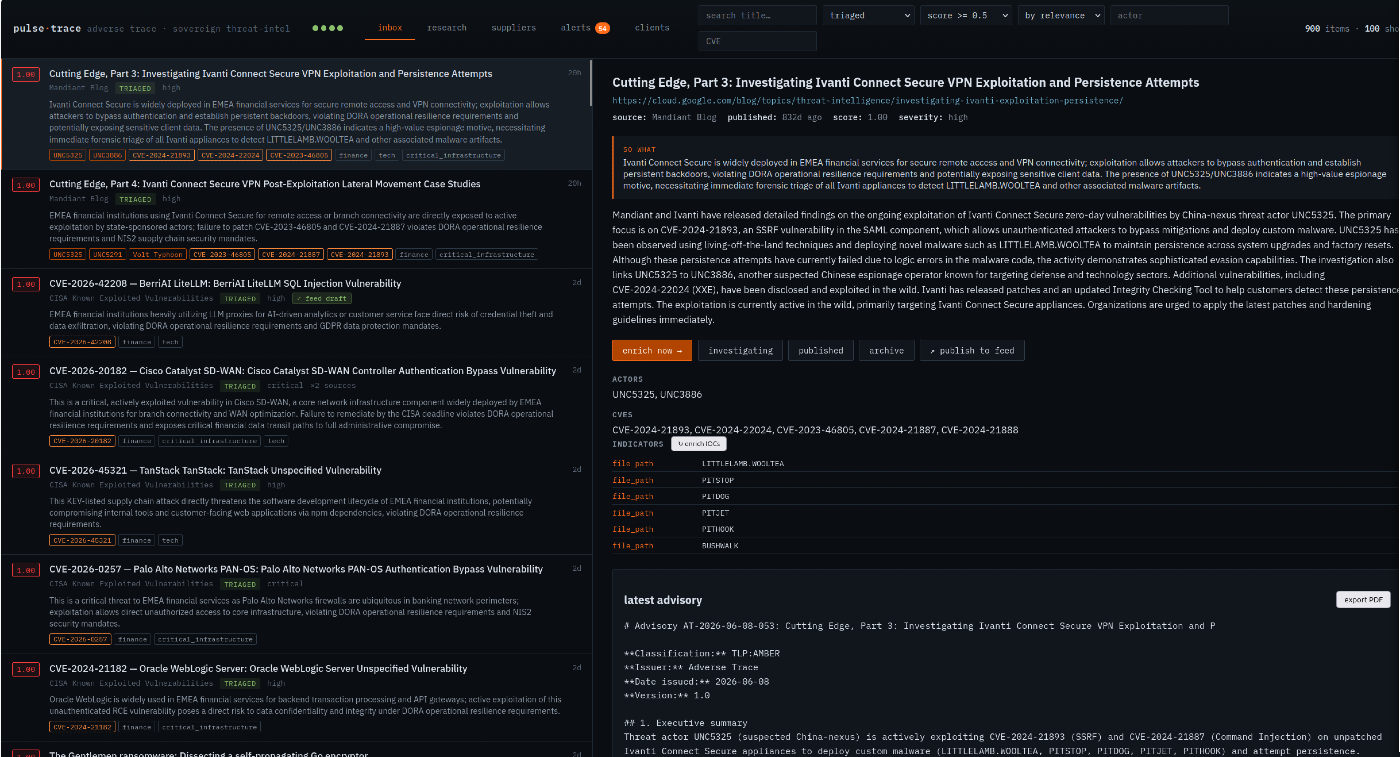
Out of one source blog it built:
- an executive summary framed around perimeter risk for financial entities specifically;
- a regulatory mapping table — DORA Art. 17 (ICT third-party risk), Art. 19 (24-hour major-incident reporting), Art. 28–30 (resilience testing), NIS2 Art. 21(2)(d) and Art. 23 — turning a generic CVE advisory into "here is your reporting clock and your obligation";
- a structured attack chain with an explicit unconfirmed steps section, because I'd rather it flag the gaps than paper over them with confident nonsense;
- an IOC table with confidence and provenance;
- working sigma and yara, with the source URL baked into the rule metadata so the detection is traceable back to where it came from.
That's the difference between a summariser and something useful. The raw feed is free and everyone has it. The bit that maps a Mandiant blog to your DORA reporting obligation and hands you a detection rule with its sources attached — that's the part the industry charges for, and that's the part worth building.
If it's of interest, I review the draft, edit it, and publish to the feed. If it's not feed material, I can render it to PDF instead.
Manual search mode
The feed is passive. The other half is active: I give the agent a query, it goes and searches, summarises what it finds, presents it, and recommends further leads to pull on. Same enrichment philosophy, just operator-driven instead of poll-driven. The output isn't a blog post either — it's a versioned, classified advisory. TLP marking, issuer block, a report ID like AT-RS-20260608-016-1, the lot. Closer to something you'd issue than something you'd publish.
So naturally, the first thing I did was point it at the very industry I'm being rude about and ask it to research "threat intel services." I iterated a few times, then generated a report — straight to PDF, because this one was never going on the feed:
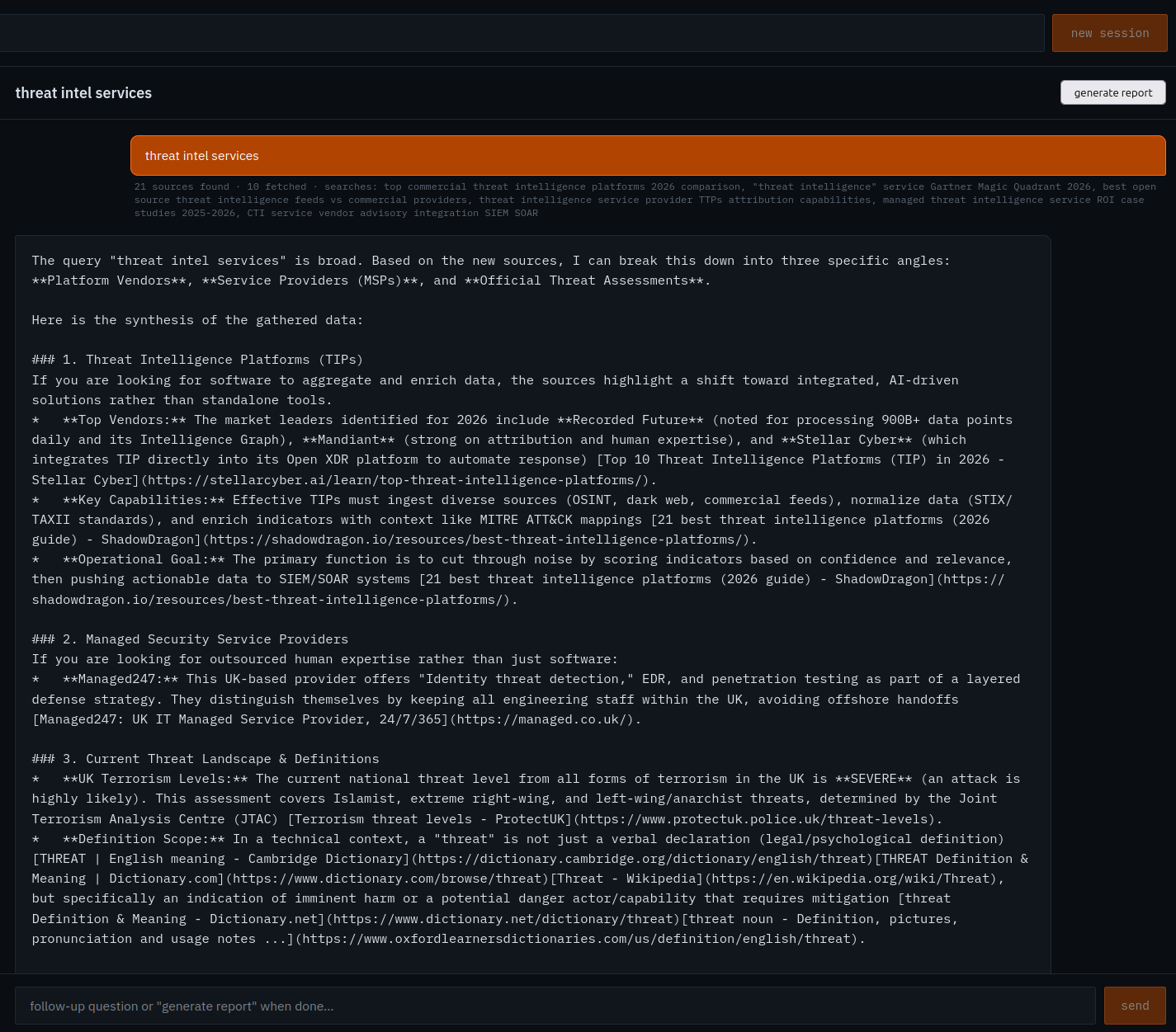
Recommended followup...lets see what it does
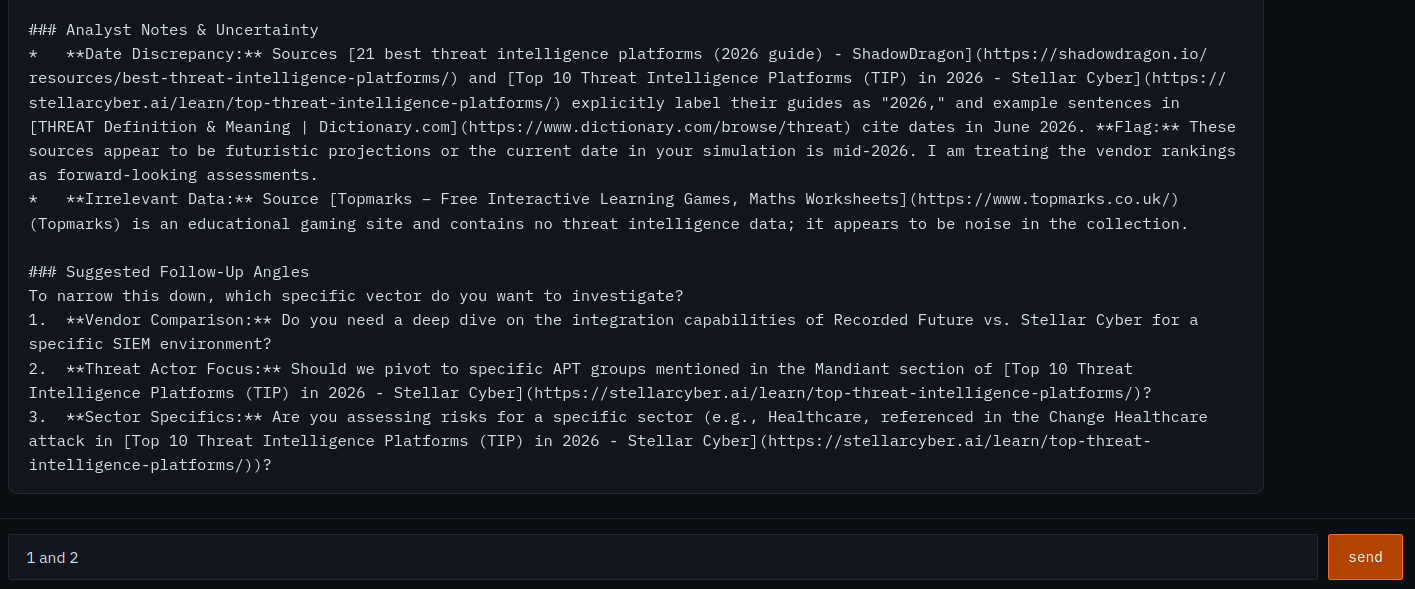
And here's the thing that made me laugh. It came back genuinely competent. A clean executive summary, a technical breakdown of platform architectures, a DORA Art. 9 / Art. 19 and NIS2 Art. 21 mapping, prioritised recommendations, and — the part I was most pleased with — a confidence assessment that rated itself MEDIUM and explained why: most of the vendor performance numbers are marketing material it couldn't independently validate, and there were no fresh IOCs to give it any tactical weight. It flagged its own thin evidence base without being asked to.
Which is exactly the point. I asked it about the threat intel industry, and it produced a polished, self-aware, regulation-mapped brief built almost entirely on vendor "best platforms of 2026" listicles. The demo proved the thesis from the inside: the underlying material is repackaged free content, and the only thing adding value was the layer sitting on top of it doing the framing and the honesty.
I'll be straight about the state of this path, though: the search-and-summarise loop and the followup recommendations work well, but the final report generation is still rough — citation hand-off and source hygiene are where it bites, and it's the edge I'm actively chasing. The workflow is all there: search → iterate → enrich → recommend → issue. The polish on that last step is a work in progress.
Why on my own infrastructure
The whole thing runs on my own hardware — the fast triage model, the 397B enrichment model, the lot. No client-adjacent data, no source content, nothing touches a third-party API. That's not a feature I bolted on for this; it's the same principle the rest of the Adverse Trace stack runs on. Sovereign by default. If I'm going to be sniffy about the threat intel industry, the least I can do is not quietly shovel everything through someone else's cloud to be clever about it.
So — is it useful?
Genuinely? For me, mostly it's a brilliant excuse to play. It's a fun problem, it stretches the cluster, and the enrichment pipeline taught me more than the output is probably worth.
But I'll concede something against my own opening: the enrichment layer changed my mind a little. A raw IOC feed is as useless as I always thought. A model that reads the whole source, frames it against the regulation that actually applies to the reader, and hands over traceable detection logic — that's a different artefact. It's not "threat intel." It's closer to "advisory triage," and that I can see a use for.
It might even be useful for someone other than me. We'll see.